mast卒社会人の制作活動
この記事は、mast Advent Calendar 2023 - Adventarの18日目の記事です。17日目は『2023年のまとめ』でした。 yudukikun5120.hatenadiary.jp
目次
自己紹介のようなもの
 mast17→CS21 (情報理工学位P)→SIerのエンジニア1年目、という人です。
mast17→CS21 (情報理工学位P)→SIerのエンジニア1年目、という人です。
mastAdCの参加は4年ぶりらしく、ギリギリ交流があった19の方々も卒業してしまったわけで、時間の流れを感じます。
興味は ↓ な感じ。

by WordCloudMaker
このためにワードクラウドを作るアプリを書いてみた。
学生時代のコードを改修してGUIを追加した程度だけど。形態素解析機能もそのうち移植したい。あとなんかバグがたくさんある。
いちおう当時はモノ作る系のmastの1人で、映像とプログラムを作っていました。 (mast20以降のモノ作る系mast生を誰1人知らないのでコロナによる分断を深く感じてます。)
ダンス部と映像作らせてもらったりとか
youtu.be
Tweetを感情分析×時系列可視化で表現したりとか
https://tomoya-onuki.github.io/som_stacked/
youtu.be
アイドルのMVメイキング撮らせてもらったりとか
youtu.be
という感じの人です。興味持ってくださった方はポートフォリオも見てください。
https://tomoya-onuki.github.io/
エンジニアリング的観点が少ないので補足紹介すると、
研究室では情報可視化を専門にツール開発に勤しんでいました。
鳥の移動データの可視化による研究者支援がテーマで、
卒論はこんな内容 →https://doi.org/10.1109/IV56949.2022.00055
修論はこんな内容 →https://doi.org/10.1109/IMSA58542.2023.10217617
です。
お仕事的にはビッグデータの分散処理システムの開発業務をしています。AWSを主に触っていて、最近はPythonをゴリゴリ書いてます。
映像につける音源どうする問題
学生の頃は周りに音楽を作れる人がいて、私が映像、友人が音楽という感じで共作をしがちでした。
けれども、社会人になってからはなかなかそういう繋がりも持てず、自力で作曲ができるわけでもなくという感じで...
「映像につける音源どうする問題」が私のここ最近の悩みでした。
フリー音源もありです。おすすめはzukisuzuki BGM - YouTubeさん。量も多くクオリティも高いのでおすすめ。大変お世話になってます。
でもやっぱり自分の意図を入れ込みたい!という気持ちがあるので、フリー音源から脱却したいわけです。
作曲できるようになろう!と思ったりもしたのですが早々と挫折。しかし幸いなことに現代では生成AIがいろいろなものを拵えてくれらしいです。
すぐに音楽を0から自力で作るのは諦めて「プロンプト作曲」をしてやろうという姿勢にシフトしました。(社会人、時間ないし。)
生成AIを使った制作
2024年は音源を生成AIに用意させるぞ!!!
と意気込んで試験的な作品を作りました。 この秋に導入した新たな機材(Lumix GH6, LEICA DG VARIO-SUMMILUX 10-25mm/F1.7 ASPH)の試し撮りも兼ねて。
そうして出来上がったものが ↓ です。
驚いたのは生成AIの性能で、ちゃんと曲になってる(気がする)。
これからの制作にやはり生成AIはかかせないなぁと思いました。
MusicGenの紹介
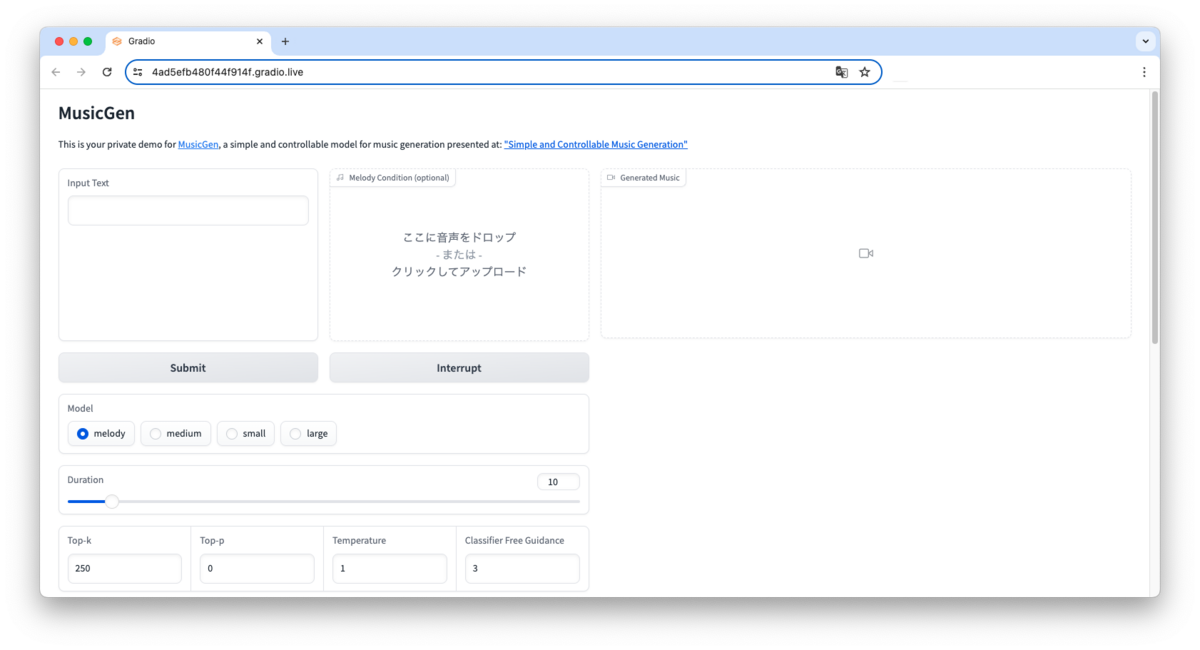
Metaが開発したMusicGenという生成AIツールを利用しています。
GoogleColab上で実行すると、いい感じのGUIが立ち現れます。
そうしたらいい感じのプロンプトを入力するだけです。
(HuggingFace上でサクッと動かすこともできるが、15秒までしか生成できない制約がある。MusicGen - a Hugging Face Space by facebook)
いろいろと試行錯誤しThe genre is hogehoge. The theme is fugafuga.というフォーマットのプロンプトを投げると良さそうだなぁとなりました。この「fugafuga」の部分に自分のポエムをぶちこみます。
ポエムは長すぎるとカオスな音源が生成されがちなので、できるだけ短くてかつキーワードを含めた英文が良さそうということも、試した知見として得られています。偶発性も狙って暗喩も織り交ぜます。
(短文でキーワードが含まれるって、俳句が最適なのでは?という気もしている。haiku promtに特化した生成AIで誰か卒論かいて。)
同じプロンプトでも生成するたびに違う音源が出力されます。なので何度か生成を繰り返して、しっくりくるモノを採用するようにしています。
さらに動画編集ソフト上でボリュームに緩急をつけるなどの簡単な微調整をしてあげます。
(自分の音源をパラメータとして用いることもできるので、ワンフレーズだけ作ってそれをベースに生成してもらうとかも今後試したいところです。)
所感
正直なところ素人耳ではAIが作った音源とはわからないものになったように思います。
こうなると生成AIで作ったことそのものが持つ単純な面白みは失われていく気もします。AIが作ったよといってグチャグチャな出力を見て喜ぶような時代は終わりですね。
一方で、誰しもが好きな方法で好きなように好きなモノを作れる(そして作らなくてもいい)という時代が加速するはず。たぶん。そして、そうならとても嬉しい。
わたしのような「音源作れなくて、作る勉強するのは面倒だけど、映像に音源は付けたくて、ただしフリー素材は嫌だ」というクソわがままも受け入れてくれる生成AIちゃんに感謝しかないです。
限られた時間と資源の中で、大切にしたい部分を守りつつ、生成AIも活用しながら、自分の思うままに作り続ける人がたくさんいると嬉しいです。